Knowledge Engineering
Natural Language Processing UX
We study financial data
to make it useable
and useful.

Intro
People recognize objects or phenomena through the sensory organs: namely, the eyes, ears, nose, mouth and the skin. Newly-acquired data is sent to the brain, and on which it makes judgments and deductions. How does a computer, which has AI applied, recognize and make judgments and deductions on data in the same way as humans?
Knowledge engineering is an important AI research area that enables machines to “think” like humans. Research on knowledge engineering began in the 1960s through studies of the “expert system.”
From the 1960s through the 1980s, knowledge was gained from experts and then saved into a database and shared. In the 1990s, the emergence of the Internet made it possible to access an immense quantity of diverse data. Today, technology has advanced to the point that we can extract and utilize useful data appropriately.
The start of the big data era has made it possible to study knowledge engineering with the application of diverse learning technologies.
What is
Knowledge
Engineering?
Since 2018, HIT has studied finance-specific knowledge engineering technologies. Focus is particularly given to research on effectively transforming financial data into knowledge for provision to people or other machines. Technologies on knowledge engineering can be divided into five major stages. The first stage, knowledge acquisition, centers on how to extract useful data from legacy data (products, e-finance, regulations, etc.) or work techniques. Second, knowledge representation focuses on how to best express extracted data and turn it into knowledge. (This stage requires knowledge representation elements and modeling technologies specialized for the financial domain.) Third, knowledge construction deals with how to extract as much knowledge as possible automatically, without human interference. Knowledge that is accumulated systematically is better utilized. The fourth is the knowledge learning stage, in which knowledge is embedded or learned through methods that are currently very popular (deep learning, fortified learning, etc.). Finally, knowledge utilization deals with how the knowledge gained from the previous four stages can be used efficiently. These five steps will eventually evolve through inter-connection and consistent repetition and improvement.
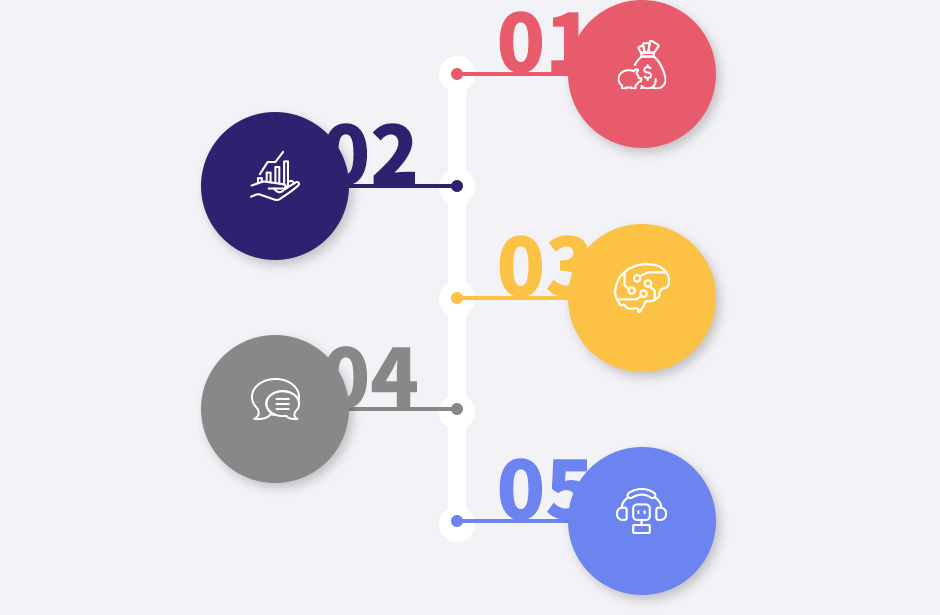
Acquisition
-
Knowledge
Acquisition -
· Financial data
(products, services,
regulations, etc.) - · Work methods/know-how
Representation
-
Knowledge
Representation -
· Extraction of expressive
elements of financial
knowledge -
· Modeling of financial
knowledge-related
expressions
Construction
-
Knowledge
Construction -
· Establishment of a basis
for financial knowledge -
· Automatic knowledge
construction
Learning
-
Knowledge
Learning - · Knowledge embedding
-
· Natural language-based
knowledge learning
Utilization
-
Knowledge
Utilization - · Chatbot / voice secretary
- · Counseling/task assistant
Future Research
HIT is currently applying a knowledge-based Q&A system to its financial chatbots and consulting assistants. The goal is to provide in-depth answers and information on work techniques (unable to be provided in the past) to customers and employees as quickly and accurately as possible. To do this, efforts will continue on R&D for new technologies (automatic knowledge production/use [as opposed to traditional Q&A methods], providing individually-tailored data) and turning such technologies into actual services. One area of particular interest for HIT is to apply, through close cooperation with the NLP sector, not only Q&A technologies but technology on producing dynamic conversation, improving knowledge and evolution. The ultimate goal is to lead technological development to provide “one AI technology per person” in the future, in the form of virtual secretaries, virtual friends and the like.